In an era of rapid technological advancement, monitoring innovation through patents has become essential for governments, businesses, and research institutions. As part of a research initiative funded by SciencesPo Paris, I developed a robust machine learning workflow to automatically classify patents by emerging technologies — including quantum computing, artificial intelligence (AI), biotechnology, and others — using a Large Language Model (LLM) fine-tuned specifically for patent texts.
This blog post outlines the complete methodology behind the project, focusing on data collection, model selection, training strategy, performance evaluation, and limitations. The approach was designed to be reproducible, scalable, and precise. Since there were more than 8 key technologies to study, I will focus in this article on AI patents. But it works the same for all technologies.
Model Selection: The Case for PatentBERT
BERT (Bidirectional Encoder Representations from Transformers), developed by Google, marked a breakthrough in Natural Language Processing by enabling deep, bidirectional understanding of text. Unlike generative LLMs such as GPT, which are primarily designed for text generation, BERT is better suited for classification tasks thanks to its encoder-only architecture. PatentBERT, a specialized version of BERT, is further optimized for the structure and language of patent documents — which are long, technical, and domain-specific.
Compared to rule-based or keyword-matching systems, BERT-based models are capable of capturing semantic nuances and handling lexical variability. This makes them especially effective for patent classification, where the same technological concept can be described using vastly different terminologies.
Fine-tuning PatentBERT — adapting it to a task-specific dataset — allows the model to specialize in identifying specific technology domains based on patent abstracts, thereby enhancing both accuracy and generalization.
Building the Training Dataset
A key step was to create a labeled dataset suitable for supervised training. Since no off-the-shelf dataset existed, we built one in several phases:
1. Keyword-Based Extraction
I started by querying the PATSTAT database for English-language patent abstracts using a curated list of keywords specific to each emerging technology. This provided an initial corpus of potentially relevant patents for AI class.
2. Random Sampling and Manual Verification
From this initial corpus, a randomly selected subset of patents was manually reviewed to confirm or reject relevance. To scale the labeling process beyond manual review, I relied on LLMs (OpenAI API) to assess whether each abstract matched its assigned label. The LLMs evaluated large portions of the dataset, flagging misclassifications and increasing overall label consistency.
3. LLM-Based Label Verification
Following the success of this semi-automatic validation, the LLM-based approach was generalized and applied to to complete the sample with non-AI patents. This allowed me to expand the dataset significantly without fully manual annotation (quite difficult), while still preserving quality.
The final labeled dataset contained 7,000 patents, evenly balanced between positive and negative classes (e.g., 3,500 related to AI and 3,500 not related to AI). I split the dataset into 80% for training and 20% for evaluation, ensuring the model had sufficient unseen data to test its generalization capability. All data was stored in Google Cloud Storage (GCS) for seamless access during both training and inference.
Preprocessing and Tokenization
Patent abstracts were cleaned to remove irrelevant characters and formatting noise. We applied the BERT-specific tokenizer, which segments text into subword units (tokens). This allows the model to better handle rare or compound terms, which are common in technical literature.
Training the Model
The model was trained by fine-tuning PatentBERT using a classic classification setup. Key concepts include:
- Batch Size: I used a batch size of 8 — balanced between training speed and memory constraints on GPU.
- Epochs: 5 epochs were sufficient to ensure good convergence without overfitting.
- Optimizer: AdamW, a variant of Adam that includes weight decay to regularize training.
- Learning Rate: A modest learning rate (2e-5) helped stabilize training and avoided oscillations.
Training was done on Google Colab Pro using a V100 GPU, which drastically reduced training time. The model’s architecture included PatentBERT and a final classification layer.
The trained model was evaluated on a held-out test set of 1,400 patents. Key metrics included:
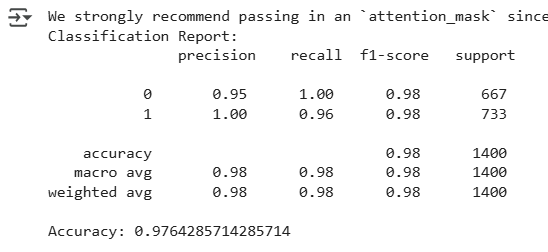
These metrics indicate a strong ability to distinguish between classes with very few false positives or false negatives.
Infrastructure for Large-Scale Inference
After training the model in Google Colab Pro, the next challenge was to apply it to the full corpus of patent abstracts — over 88 million entries — stored in Google Cloud Storage (GCS).
While using a GPU for inference would have significantly reduced processing time, the associated costs were prohibitive in the context of this project. As a result, I opted for a more cost-effective setup: a Google Compute Engine (GCE) instance with 8 vCPUs and 32GB RAM. This configuration offered a good balance between affordability and performance for large-scale, CPU-based inference.
To handle the data volume efficiently:
- Patent data was streamed in batches directly from GCS.
- For each batch, the model predicted the technology classification.
- Patents identified as relevant were written incrementally to a GCS
Despite the absence of GPU acceleration, the inference process completed in approximately 11 hours, demonstrating that a well-structured pipeline can scale effectively even on CPU infrastructure. This also highlights the benefit of decoupling training and inference environments, allowing model application in more constrained or cost-aware deployment contexts.
Limitations and Future Work
While the model performed very well, a few limitations are worth noting:
- Limited Training Diversity: The labeled dataset may not fully capture all subdomains of a technology (e.g., AI in healthcare vs. AI in robotics), limiting generalization.
- Keyword Bias: The initial keyword filtering may have biased the sample by excluding patents that use alternate terminology.
Improvements could include active learning strategies, domain-adaptive pretraining, and better sampling strategies to diversify the training set.
Final Thoughts
This project demonstrates the power of LLMs — and particularly domain-specific models like PatentBERT — for automating high-stakes classification tasks in the IP landscape. With the right data pipeline, training strategy, and infrastructure, it’s possible to process massive datasets with precision.
Whether you’re tracking innovation trends, supporting R&D, or doing policy work, scalable LLM pipelines can unlock new value from patent data.
You can explore the full pipeline and implementation details in the GitHub repository:
🔗 Patent Classification on GitHub
Subscribe to newsletter
Get new essays directly in your inbox.